思路
基本思路:找一个基准数(pivot),遍历[left, right]区间,比基准数小的数放在它的左边,比基准数大的放在它右边。此时这个基准数所在位置就已经确定了(每次遍历都会确定当前基准数的位置)。随后递归地去排它左边部分和右边部分,直到数组有序。
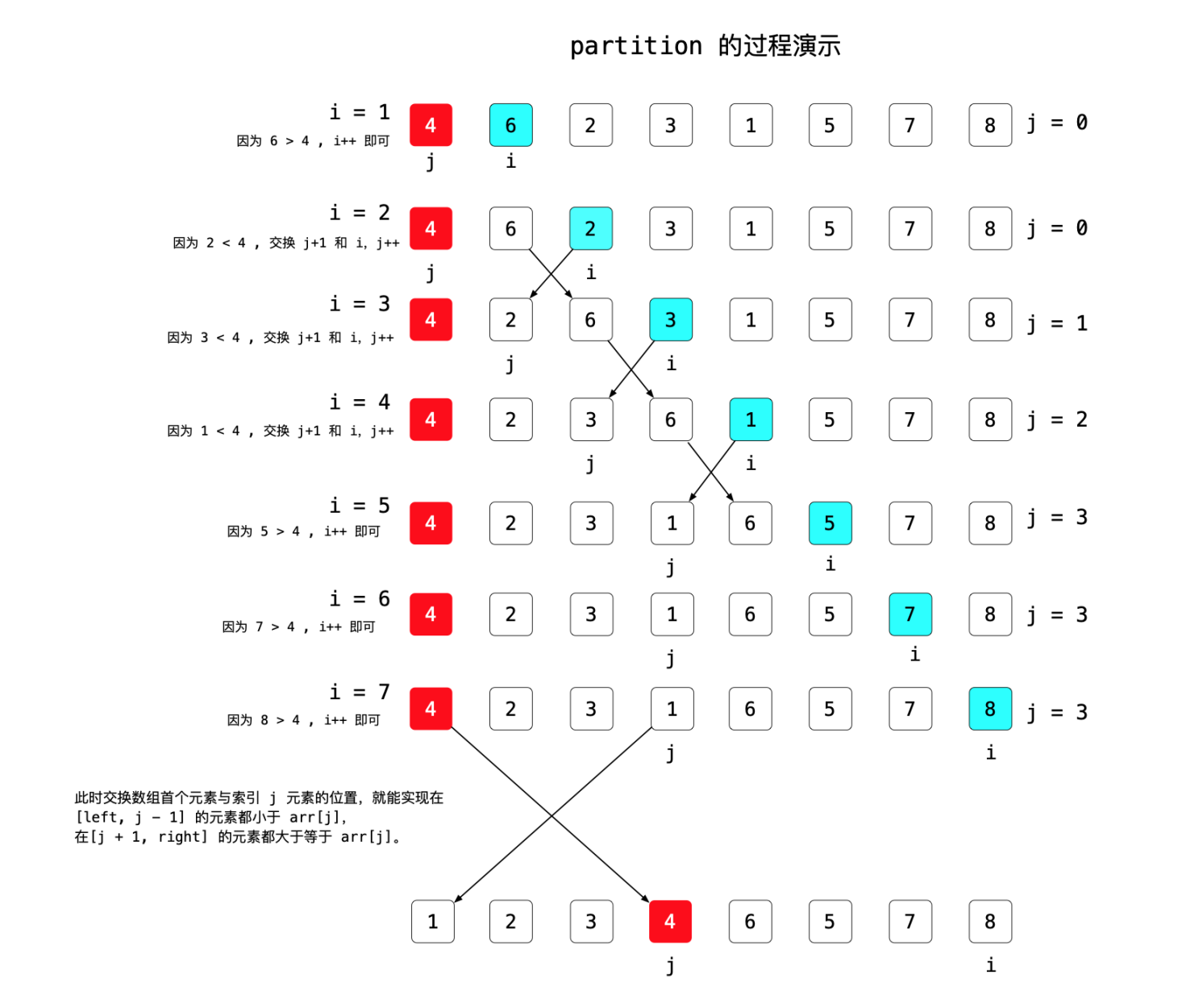
通过基准数将当前数组一分为二的过程称为:切分(partition)
切分
切分的步骤:
- 先选出一个元素作为基准数(pivot)
- 经过一次扫描,将当前区间分为两部分
- 都小于基准数的部分
- 都大于大于基准数的部分
- 最后交换 基准数与小于基准数部分的最后一个元素的位置,此时基准数的位置被确定
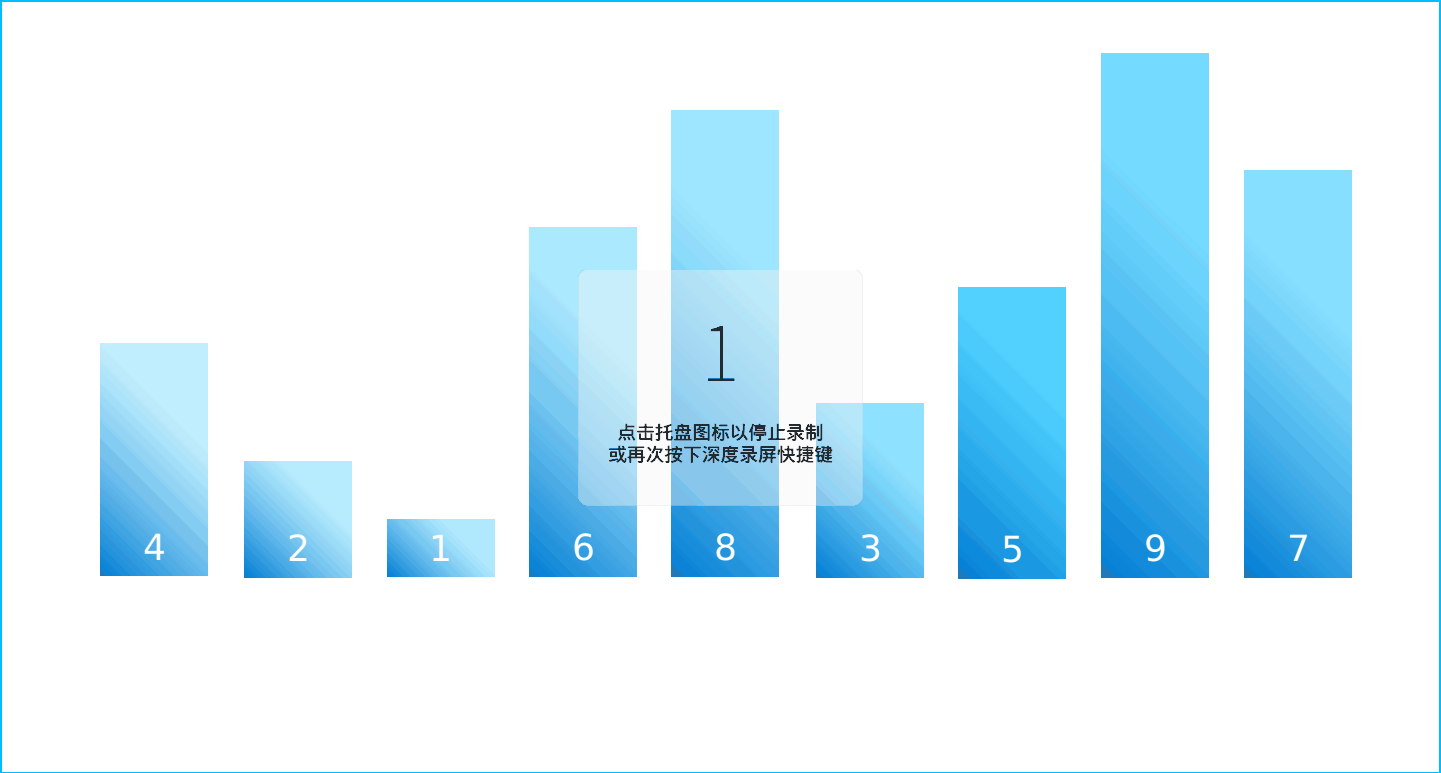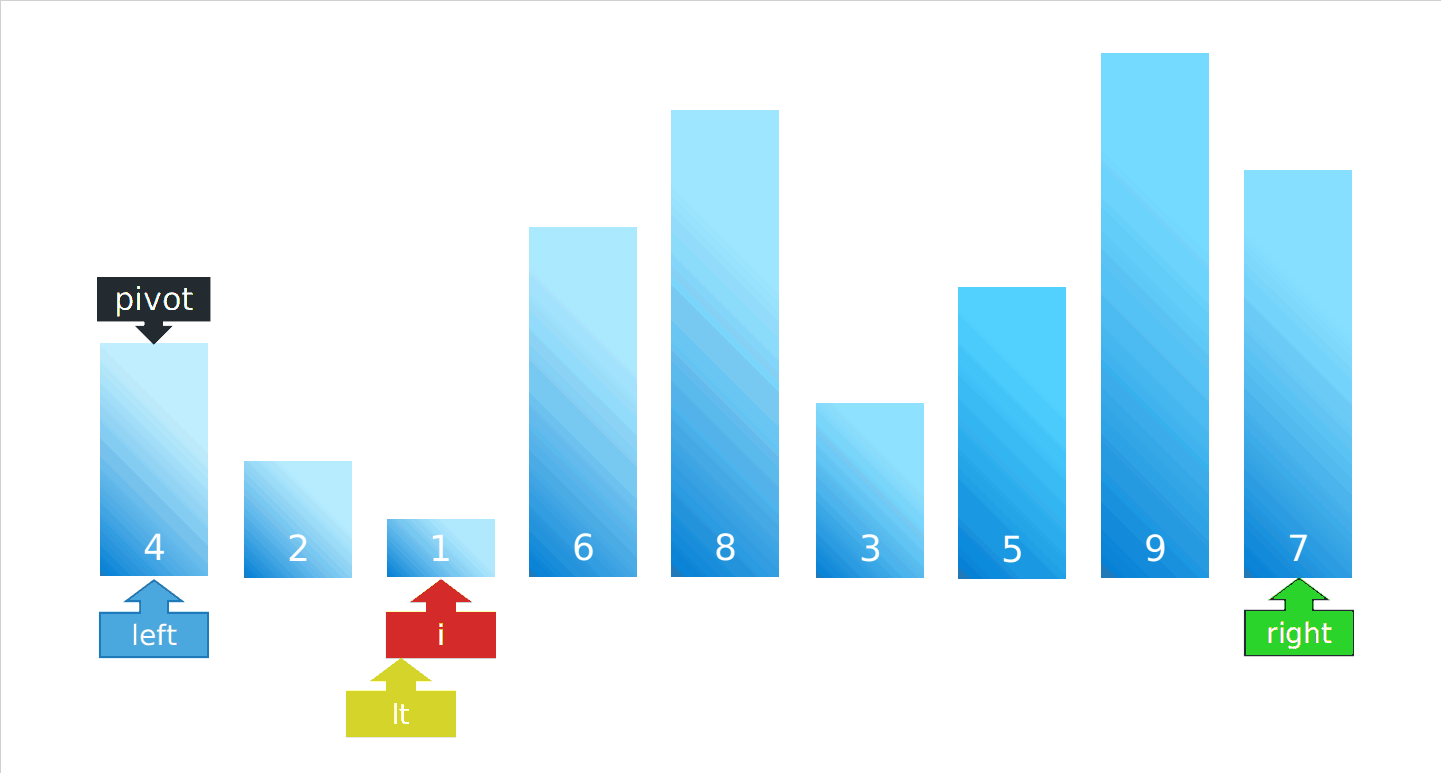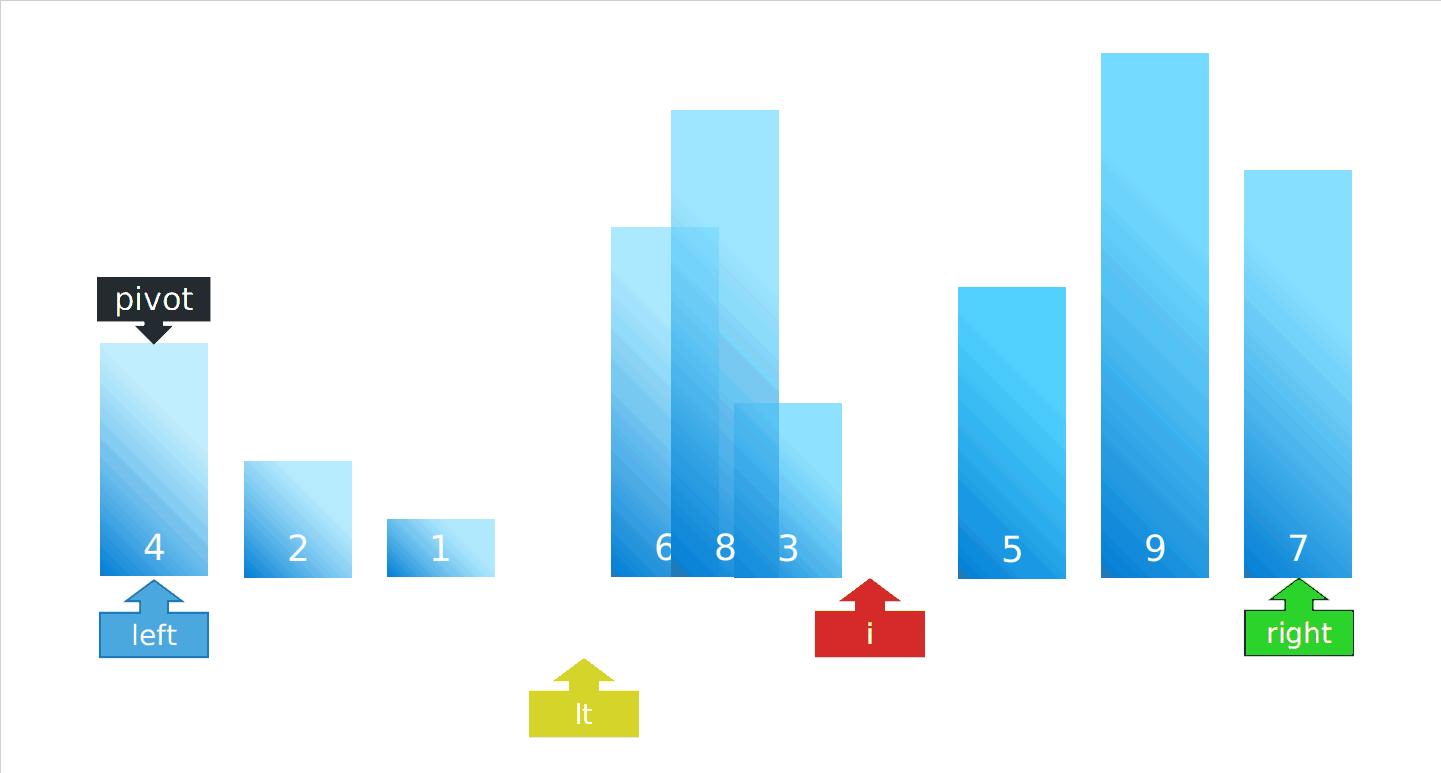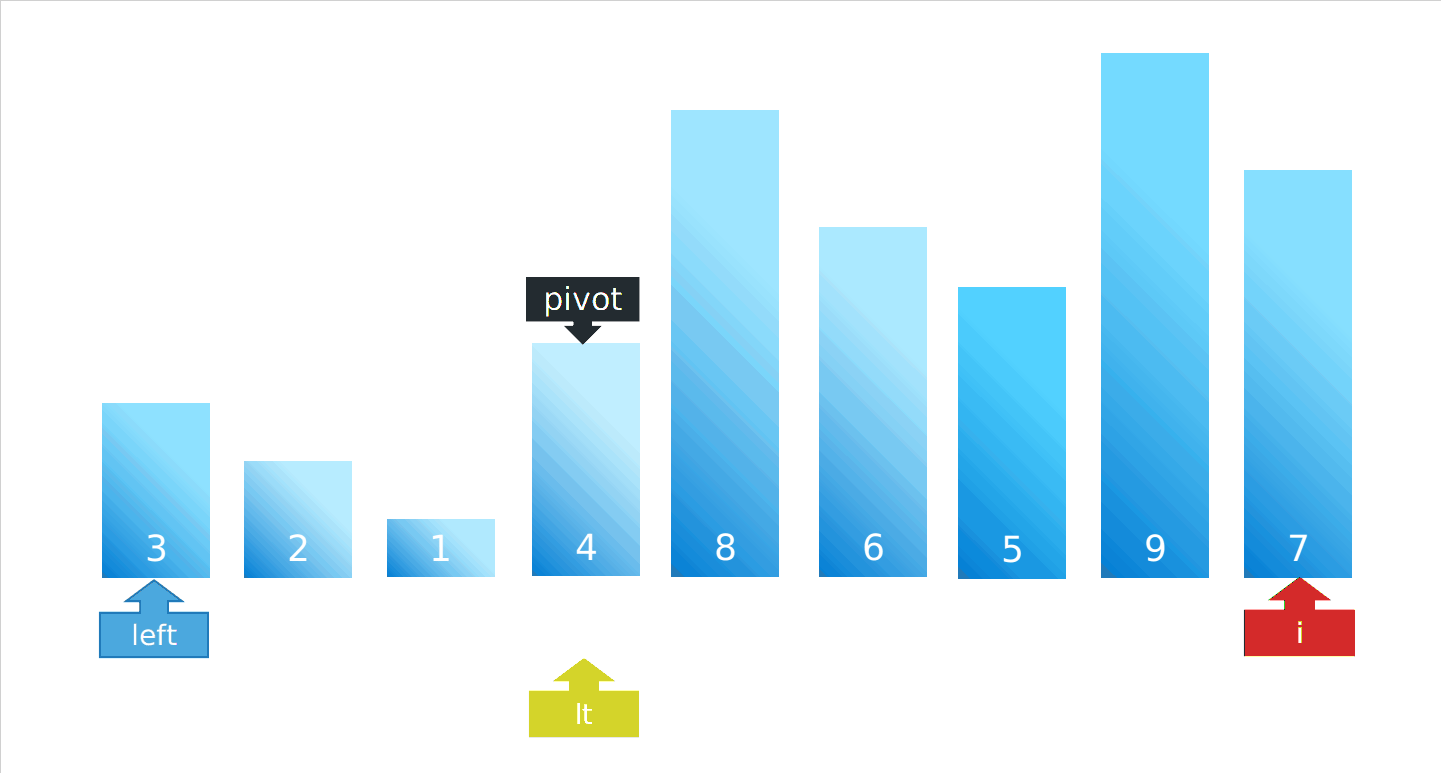
partition步骤演示图:
边想边写
- 顶层函数
def test_quick_sort(arr):
arr = [9,2,1,6,3,7]
# 调用快速排序函数
quick_sort(arr, 0, len(arr) - 1)
- 快速排序主函数
通过 切分函数 获取基准值最终位置,通过基准值将当前区间一分为二
def quick_sort(arr, left, right):
if left >= right:
return
p_index = partition(arr, left, right)
quick_sort(arr, left, p_index)
quick_sort(arr, p_index + 1, right)
- 切分函数
完成一轮遍历,并将当前区间按基准值分割为 「小于基准值部分」和 「大于等于基准值部分」
此处返回 基准值所处位置,实际一分为二的操作是在
quick_sort中
def partition(arr, left, right):
lt = left
# 基准值
pivot = arr[left]
# 从基准值的后面一位开始遍历
for i in range(left + 1, right + 1):
if arr[i] < pivot:
# lt 移动到了i上面
lt += 1
# 与基准值的位置互换
arr[i], arr[lt] = arr[lt], arr[i]
# 遍历结束,将基准值与比基准值小的部分的最后一位元素互换位置
arr[lt], arr[left] = arr[left], arr[lt]
return lt
代码
def partition(arr, left, right):
pivot = arr[left]
lt = left
for i in range(left + 1, right + 1):
if arr[i] < pivot:
lt += 1
arr[i], arr[lt] = arr[lt], arr[i]
arr[left], arr[lt] = arr[lt], arr[left]
return lt
def quick_sort(arr, left, right):
if left >= right:
return
p_index = partition(arr, left, right)
quick_sort(arr, left, p_index)
quick_sort(arr, p_index + 1, right)
def quick_sort_test():
arr = [0, 2, 5, 1, -4]
quick_sort(arr, 0, len(arr) - 1)
print(arr)
动图演示
上方代码执行一次快排的演示(如果做全程演示,眼睛都要花了,哈哈哈)
完整的快速排序可视化演示可以看这里 https://visualgo.net/zh/sorting
优化
- 小区间使用「插入排序」
回顾下插入排序
"""插入排序(赋值版)"""
def insert_sort(arr, left, right):
for i in range(left + 1, right + 1):
temp = arr[i]
p = i - 1
while p >= left and arr[p] > temp:
arr[p + 1] = arr[p]
p -= 1
arr[p + 1] = temp
在短序列的情况下,「插入排序」更占有优势!
排序16位序列
快速排序: 耗时 0.000043 秒。
插入排序: 耗时 0.000011 秒。
所以在进行切分之前,可以判断当前区间的长度,小于16则将此区间拿去做 「插入排序」
def quick_sort(arr, left, right):
if left >= right:
return
# 优化1
if right - left <= 15:
insert_sort(arr, left, right)
return
p_index = partition(arr, left, right)
quick_sort(arr, left, p_index)
quick_sort(arr, p_index + 1, right)
- 随机选择基准元素, 降低递归树结构不平衡的情况
对于 「接近有序的序列」 ,快排的效果将变得极其差劲,效率将和 「冒泡排序」差不多
接近有序的序列(1000个数)
快速排序: 耗时 0.036063 秒。
冒泡排序: 耗时 0.037795 秒。
为什么会这样?
https://blog.csdn.net/weshjiness/article/details/8660583
快速排序的时间性能取决于快速排序递归的深度,可以用递归树来描述递归算法的执行情况
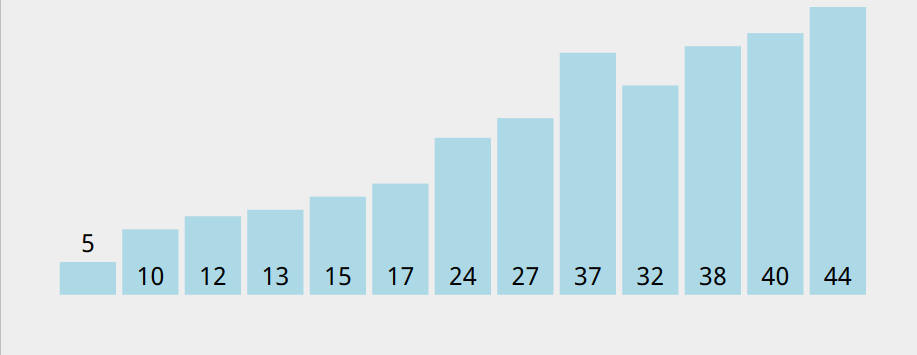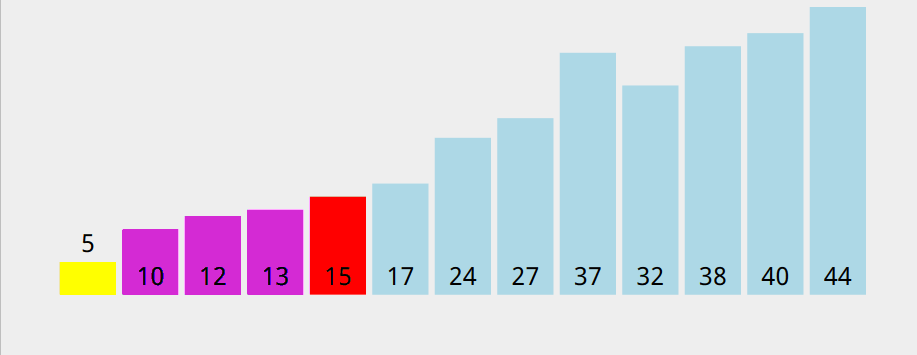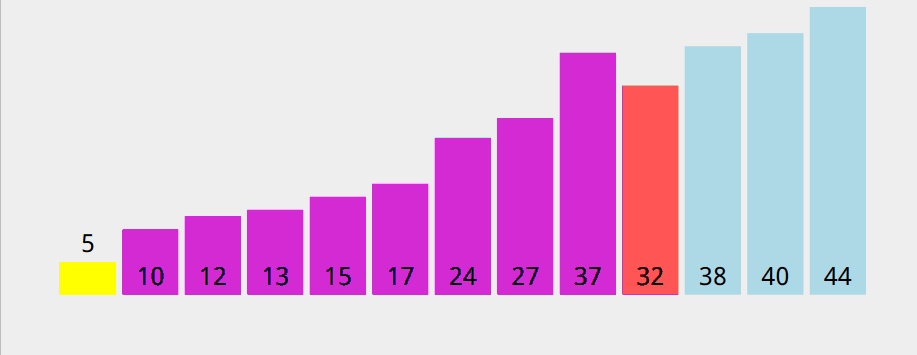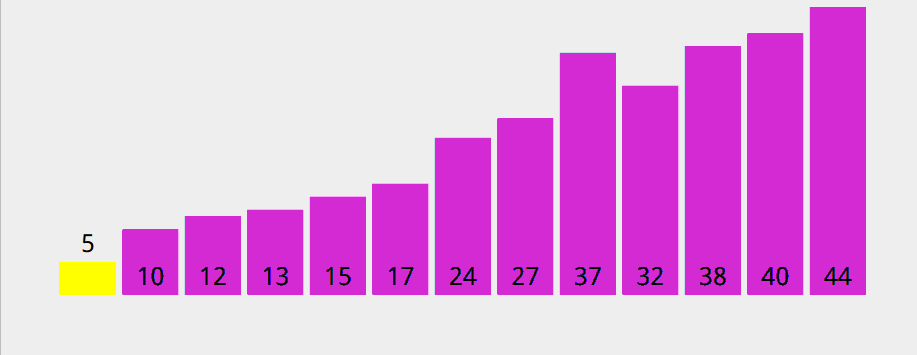
以 5 作为基准数时,递归树倾斜严重,递归的深度也很大,而快速排序的时间取决于递归树的深度。
也就说,我们选择基准数时,尽量使得整个递归树平衡(或者说不要过于倾斜)
解决方案: 我们在每一次迭代开始之前,随机选取一个元素作为基准元素与第 1 个元素交换即可。
random_index = random.randint(left, right)
arr[left], arr[random_index] = arr[random_index], arr[left]
def quick_sort(arr, left, right):
if left >= right:
return
# 优化1
if right - left <= 15:
insert_sort(arr, left, right)
return
# 优化2
random_index = random.randint(left, right)
arr[left], arr[random_index] = arr[random_index], arr[left]
p_index = partition(arr, left, right)
quick_sort(arr, left, p_index)
quick_sort(arr, p_index + 1, right)
再对1000个数 接近有序的序列排序
快速排序: 耗时 0.003974 秒。
效果明显有所提升
总结
- 归并排序和快速排序都用到了 「分治思想」;
- 归并排序是直接一分为二,快速排序是按基准值进行分割;
- 归并排序是稳定排序,快速排序不稳定;
- 实现细节(注意事项):(针对特殊测试用例:顺序数组或者逆序数组)一定要随机化选择切分元素(
pivot),否则在输入数组是有序数组或者是逆序数组的时候,快速排序会变得非常慢(等同于冒泡排序或者「选择排序」);